2.1. HashMap。連想配列、配列添え字がなんでもOK。¶
HashMapは連想配列です。
配列の添え字が正の整数でないといけないですが、連想配列は添え字が文字列でもオブジェクトでもOKです。
なにかと便利なのでよく使われます。
例えば:
配列:array_sweets [0]="綿あめ"、sweets [1]="モンブラン"... 添え字が整数
連想配列:hashmap_sweets ["雲"]="綿あめ"、sweets ["栗"]="モンブラン"... 添え字が文字列オブジェクト
※連想:ある事柄から、それと関連のある事柄を思い浮かべること。
配列array_sweets
添え字 |
0 |
1 |
... |
値 |
綿あめ |
モンブラン |
... |
連想配列hashmap_sweets
添え字 |
雲 |
栗 |
... |
値 |
綿あめ |
モンブラン |
... |
添え字のオブジェクトをhash演算して数値に置きなおして配列にアクセスするため、通常の配列に近い速度性能を出します。
※hash演算の性能は重要です。できるだけ、速くてバラケてほしい。
目次
2.1.1. クラス図へ変換¶
では、早速クラス図にしてみましょう。
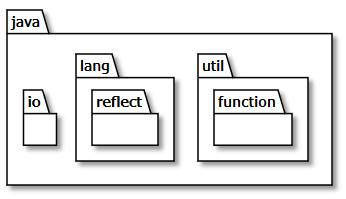
UML変換くんを実行。
> touml .\java\util\HashMap.java -o d:\temp
※java1.8コード
※「-o d:temp」はクラス図の出力先です。

2.1.2. 継承を眺めてみる¶
2.1.2.1. Mapを実現しています。¶
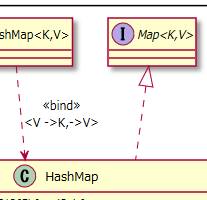
MapはxxxMapのようなMap機能をもつクラスを作るときに実現するインタフェースです。
mapの意味は「地図、天体図、星座図、図解、図表」です。
つまり、要素にキーをつけた表を作るイメージです。
2.1.2.2. AbstractMapを継承しています。¶
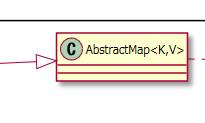
AbstractMapはMap機能を持つクラスの親クラスです。
Map機能の共通部分をこのクラスにまとめています。
ですので継承しています。
2.1.3. フィールドを眺めてみる¶
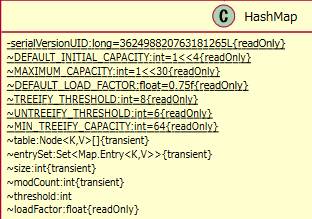
2.1.3.2. DEFAULT_INITIAL_CAPACITY¶
~DEFAULT_INITIAL_CAPACITY:int=1<<4{readOnly}
標準格納容量です。1<<4はシフト演算で1*2^4と同じで16です。
※この項目は2のべき乗であるという縛りがあるそうです。
2.1.3.3. MAXIMUM_CAPACITY¶
~MAXIMUM_CAPACITY:int=1<<30{readOnly}
格納容量の最大値です。
※この項目は2のべき乗であるという縛りがあるそうです。
※1<<30は1*2^30のことです。
2.1.3.4. DEFAULT_LOAD_FACTOR¶
~DEFAULT_LOAD_FACTOR:float=0.75f{readOnly}
標準の負荷係数です。
※閾値(キャパシティ×負荷係数)を決めるのに使っています。
2.1.3.5. TREEIFY_THRESHOLD¶
~TREEIFY_THRESHOLD:int=8{readOnly}
ハッシュキーが衝突した時のbin(要素の置き場)をリストからツリーに置き換えるための閾値。
※binのリストがこのサイズを超えるとツリーに変換されて非効率な処理を避ける。
2.1.3.6. UNTREEIFY_THRESHOLD¶
~UNTREEIFY_THRESHOLD:int=6{readOnly}
bin(要素の置き場)をリストからツリーに置き換えるのやめるための閾値。
2.1.3.7. MIN_TREEIFY_CAPACITY¶
~MIN_TREEIFY_CAPACITY:int=64{readOnly}
bin(要素の置き場)をツリー化できる最小のテーブル容量。
※bin内のノードが多すぎる場合、テーブルのサイズが変更されます。
2.1.3.13. loadFactor¶
~loadFactor:float{readOnly}
負荷係数。thresholdを導く。
※threshold =capacity * load factor
2.1.4. メソッドを眺めてみる¶
2.1.4.2. comparableClassFor¶
~comparableClassFor(x:Object):Class<?> ~compareComparables(kc:Class<?>,k:Object,x:Object):in t
どちらもstaticメソッドです。
comparableClassForは引数xがComparableを実現しているクラスの場合そのクラス型(Class<?>)を返します。
compareComparablesは引数kと引数xを大小比較してその結果を返します。
ただし普通のcompareToと違うのは、引数xが引数kcのクラス型と同じかどうかもチェックしています。
これらのメソッドはセットで使っています。
else if ((kc != null ||
(kc = comparableClassFor(k)) != null) &&
(dir = compareComparables(kc, k, pk)) != 0)
2.1.4.3. tableSizeFor¶
~tableSizeFor(cap:int):int{readOnly}
引数capのキャパシティ値を閾値(threshold)に変換する。
下記のようにビット演算して値を求めている。
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
2.1.4.4. コンストラクタ¶
+HashMap(initialCapacity:int,loadFactor:float):void
+HashMap(initialCapacity:int):void
+HashMap():void
+HashMap(m:Map<?extends K,?extends V>):void
引数initialCapacity(初期容量)と引数loadFactor(負荷係数)を渡して作成している。
※負荷係数はデフォルトでは0.75となっている。要素の合計がこの割合を超えると容量を拡張するためにリサイズする。
2.1.4.5. putMapEntries¶
~putMapEntries(m:Map<?extends K,?extends V>,evict:boolean):void{readOnly}
引数m(Map)の要素の集合を追加します。
引数evict(立ち退かせる)はMapを始めて作るときにはfalseを設定し、途中でputする場合にはtrueをセットしています。
2.1.4.7. get¶
+get(key:Object):V
~getNode(hash:int,key:Object):Node<K,V>{readOnly}
getは引数keyに対応する値Vを取得します。
getNodeはgetメソッド内で使われていて、引数hashと引数keyを元に要素を返却します。
2.1.4.9. put¶
+put(key:K,value:V):V
~putVal(hash:int,key:K,value:V,onlyIfAbsent:boolean,evict:boolean):V{readOnly}
putは引数kと引数valueを内部テーブルに追加します。
putValはput内で使われています。
2.1.4.11. treeifyBin¶
~treeifyBin(tab:Node<K,V>[],hash:int):void{readOnly}
引数tabのテーブルの引数hashの位置をツリー構造に置き換えます。
※ツリー構造にすると処理が高速化します。
2.1.4.13. remove¶
+remove(key:Object):V
~removeNode(hash:int,key:Object,value:Object,matchValue:boolean,movable:boolean):Node<K,V>{readOnly}
+clear():void
removeは引数keyに対応する要素をテーブルから削除します。
removeNodeはremove中で使われている内部のメソッドです。
clearはテーブル内の要素をすべて削除します。
2.1.4.15. keySet¶
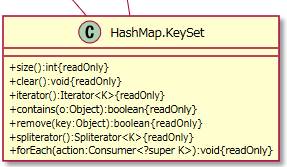
+keySet():Set<K>
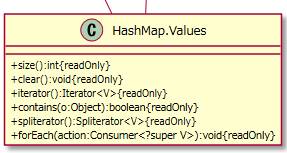
+values():Collection<V>
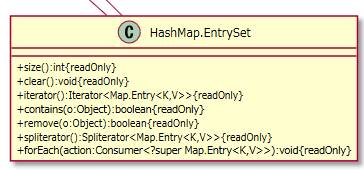
+entrySet():Set<Map.Entry<K,V>>
keySetは内部テール内のキーの集合を返します。
valuesは内部テール内の値の集合を返します。
entrySetは内部テール内の値のキーのペアの集合を返します。
2.1.4.16. getOrDefault¶
+getOrDefault(key:Object,defaultValue:V):V
引数keyに対応する値を返却します。値がないときには引数defaultValueを返します。
2.1.4.19. replace¶
+replace(key:K,oldValue:V,newValue:V):boolean
引数keyに対応する値がoldValueの時にはnewValueに置換します。
+replace(key:K,value:V):V
引数keyに対応する値をvalueに置換します。
2.1.4.20. computeIfAbsent¶
+computeIfAbsent(key:K,mappingFunction:Function<?super K,?extends V>):V
+computeIfPresent(key:K,remappingFunction:BiFunction<?super K,?super V,?extends V>):V
+compute(key:K,remappingFunction:BiFunction<?super K,?super V,?extends V>):V
computeIfAbsentは引数keyがまだ値とマッピングされていないときには引数mappingFunctionの処理で値を作成して登録します。
computeIfPresentは引数keyが既に値とマッピングされているときには引数mappingFunctionの処理で値を作成して登録します。
computeは引数keyに対応するキーと値を引数remappingFunctionで処理させて結果を登録します。
2.1.4.21. merge¶
+merge(key:K,value:V,remappingFunction:BiFunction<?super V,?super V,?extends V>):V
引数keyで取得した値と、引数valueを引数remappingFunctionでセットした関数オブジェクトでマージして置き換えます。
2.1.4.22. forEach¶
+forEach(action:BiConsumer<?super K,?super V>):void
メソッドとしてfor eachのループを実行します。処理内容は引数actionに関数オブジェクトを書いてそれをセットします。
2.1.4.23. replaceAll¶
+replaceAll(function:BiFunction<?super K,?super V,?extends V>):void
引数functionの関数オブジェクトの処理を使って、要素の置換をします。
関数オブジェクトBiFunctionをオーバーライドして処理を実装します。
2.1.4.27. writeObject、readObject¶
-writeObject(s:java.io.ObjectOutputStream):void
-readObject(s:java.io.ObjectInputStream):void
シリアライズのときStreamへの書き込み、読み込みに使われます。
2.1.4.29. replacementNode¶
~replacementNode(p:Node<K,V>,next:Node<K,V>):Node<K,V>
TreeNodesからプレーンノードへの変換。
2.1.4.30. newTreeNode¶
~newTreeNode(hash:int,key:K,value:V,next:Node<K,V>):TreeNode<K,V>
TreeNodeを生成します。
2.1.4.31. replacementTreeNode¶
~replacementTreeNode(p:Node<K,V>,next:Node<K,V>):TreeNode<K,V>
NodeをTreeNodeにしています。
2.1.4.33. afterNodeAccess¶
~afterNodeAccess(p:Node<K,V>):void
~afterNodeInsertion(evict:boolean):void
~afterNodeRemoval(p:Node<K,V>):void
LinkedHashMapのポストアクションを許可するコールバックです。
ここでは処理は空です。
LinkedHashMapでオーバーライドして実装しています。
2.1.4.34. internalWriteEntries¶
~internalWriteEntries(s:java.io.ObjectOutputStream):void
互換性のある順序を確保するために、writeObjectからのみ呼び出されます。
シリアライズの時に使われます。
2.1.5. 内部クラス¶
2.1.5.1. EntrySpliterator¶
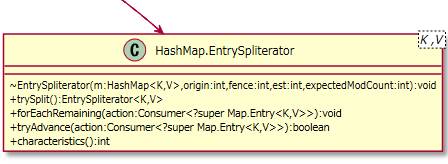
イテレーターの一種でエントリーを扱うスプリテレーターのクラスです。
HashMap.EntrySetクラスの「+spliterator():Spliterator<Map.Entry<K,V>>{readOnly}」メソッド内で使われています。
2.1.5.2. ValueSpliterator¶
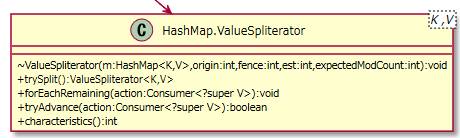
イテレーターの一種で値(value)を扱うスプリテレーターのクラスです。
HashMap.Valuestクラスの「+spliterator():Spliterator<V>{readOnly}」メソッド内で使われています。
2.1.5.3. KeySpliterator¶
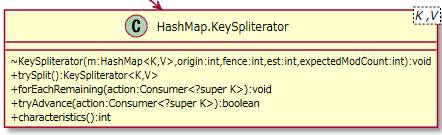
イテレーターの一種でキーを扱うスプリテレーターのクラスです。
HashMap.KeySetクラスの「+spliterator():Spliterator<K>{readOnly}」メソッド内で使われています。
2.1.5.4. HashMapSpliterator¶
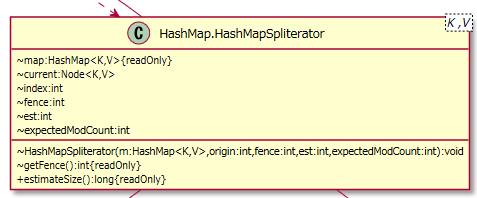
HashMap.EntrySpliterator、HashMap.ValueSpliterator、HashMap.KeySpliteratorクラスの親クラスになります。
スプリッテレーターの共通処理をまとめています。
2.1.5.8. HashIterator¶
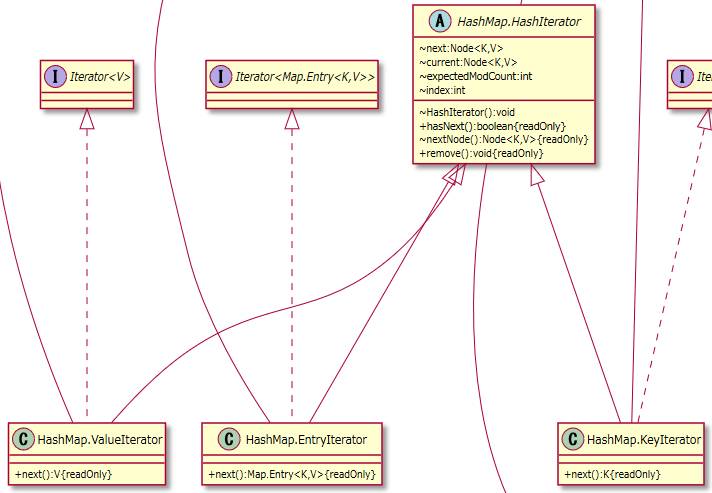
ValueIterator、EntryIterator、KeyIteratorの親クラスでありHashMapで扱うIteratorの共通処理をまとめている。
2.1.5.8.1. ValueIterator子クラス¶
値を扱うイテレータークラスです。
HashMap.Valuestクラスの「+iterator():Iterator<V>{readOnly}」メソッド内で使われています。
2.1.5.8.2. EntryIterator子クラス¶
エントリーを扱うイテレータークラスです。
HashMap.EntrySetクラスの「+iterator():Iterator<Map.Entry<K,V>>{readOnly}」メソッド内で使われています。
2.1.5.8.3. KeyIterator子クラス¶
キーを扱うイテレータークラスです。
HashMap.KeySetクラスの「+iterator():Iterator<K>{readOnly}」メソッド内で使われています。
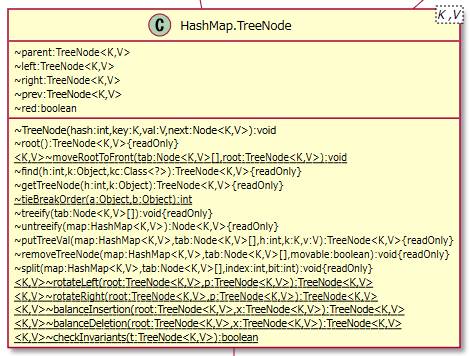
2.1.6. まとめ¶
HashMapは連想配列です。
ソースコードを調査してみると結構大きなライブラリになっていました。
内部クラスだけでも11個もありました。
同じ集合を扱うのでもArrayListとは比較にならない複雑さでした。